斗鱼体育app Rubrics综述: Agent时间, 如何界说一个「好谜底」?

频年来,跟着大模子节约单问答,走向深度筹划、医疗商讨、多模态生成和长程Agent任务,一个基础问题变得越来越难请问:咱们到底应该若何判断模子输出的质料?
在许多确切且复杂的场景中,咱们可能莫得模范谜底也莫得可验证谜底正确性的信号来评估模子输出的正确性。
以DeepResearch讲述评估为例,传统步调可能仅仅对比生成讲述和参考讲述的文本互异,或者让大模子给一个总体分数。但一篇好讲述并不一定要和参考讲述写得雷同,也很难用一个蒙眬分数详尽。它需要同期孤高多个要求,举例是否请问了用户问题、覆盖了关键信息、援用了可靠笔据、论证是否深刻、论断是否有用等等。
Rubrics的作用,等于把这些迂缓的「好讲述」模范拆解成明确的评价项,让评审者或judgemodel逐项查抄和打分。这么不仅能判断讲述总体好不好,还能指出具体问题,并进一步把这些细粒度响应转机为考试信号,匡助模子针对覆盖不及、笔据不充分或逻辑不清等问题进行优化。
这意味着,大模子的考试与评测正在从单一正确性信号,转向多维度、可讲解的质料模范。Rubrics,正在成为聚合东说念主类欲望、任务要乞降模子行径的蹙迫接口。
近日,来自中国东说念主民大学高瓴东说念主工智能学院的筹划团队发布综述论文《TheRulesoftheGame:ASurveyofRubricsforLargeLanguageModels》。论文共40页,系统梳理了Rubrics在大模子中的界说、构造步调、考试利用、评测场景与灵通挑战。论文同期退换了捏续更新的GitHub神志,便捷社区追踪这一快速发展的标的。

论文标题:TheRulesoftheGame:ASurveyofRubricsforLargeLanguageModels
GitHub阅读列表:https://github.com/RUC-NLPIR/Rubrics_Survey
为什么当今需要Rubrics?
早期大模子的任务时时具有相对深刻的输入输出面容,何况谜底的正确性是容易评估的。举例问答任务不错比较模范谜底,代码任务不错运行测试用例,数学任务不错验证最终后果。关于这些任务,准确率、引申到手率或规章化奖励大约提供较径直的考试和评测信号。
但跟着模子能力扩展,任务难度也发生了彰着变化。大模子正在被要求完成更灵通、更高风险、更复杂的任务。举例:自动搜索贵寓并生成筹划讲述;在医疗、法律、金融等专科范围给出分析;调用外部器具完成多步任务;在多模态场景中生成或认识复杂内容。此时,输出质料经常不再由一个谜底决定,而是由多个维度共同决定。
Rubrics的价值正在这里泄露出来。它将「好谜底」拆解为一组明确的评价项,举例事实正确性、覆盖度、笔据复古、推理严谨性、安全性、形状合规性和本质可用性。评测者不错逐项打分,也不错将这些分数团聚为最终后果。与一个黑箱分数比较,Rubrics提供的是可查抄、可调节、可会诊的质料模范。
本文聚焦于请问以下五个问题:
Rubrics是什么?
Rubrics如何构造?
Rubrics如何用于模子考试?
Rubrics如何用于任务评测?
灵通性问题和挑战
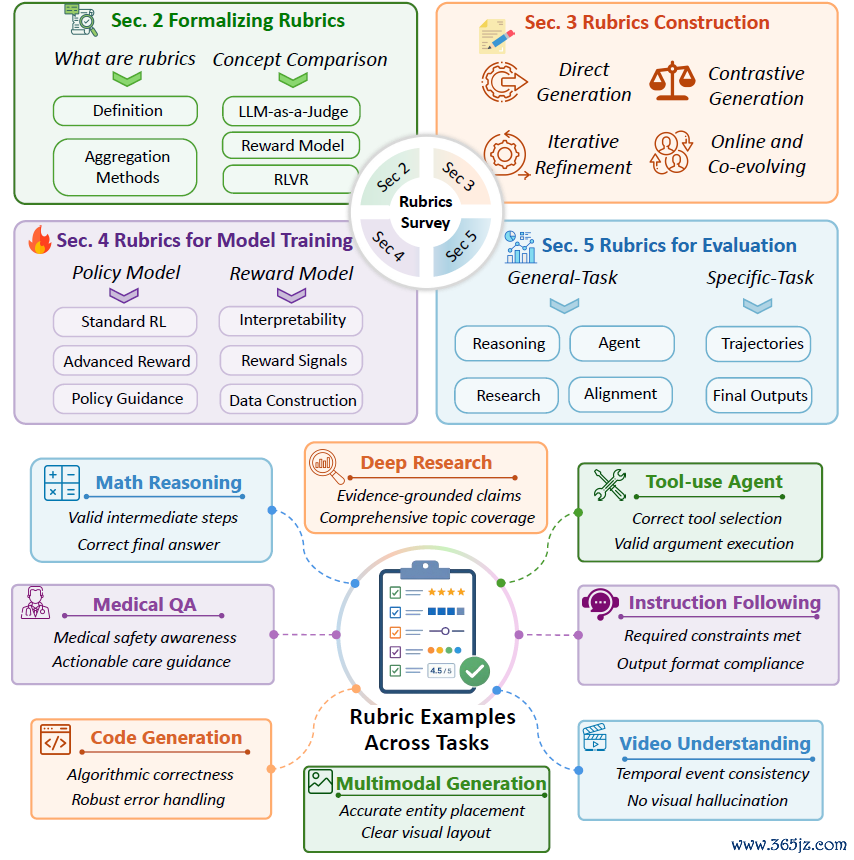
图1:上半部分是章节总览;下半部分展示了rubrics在不同任务上的示例。
Rubrics到底是什么?
在教学评估中,rubric经常指一套评分指南:它证实评估者应该看哪些方面,以及不同质料水中分别意味着什么。放到LLM中,Rubrics不错认识为一组当然谈话面容的评价模范,每个模范对应一个具体、可评估的质料维度。
这篇综述给出了和洽面容化:一个rubricset不错由若干rubricitem构成,每个item包含当然谈话描写(具体的rubrics示例不错参见图1下半部分)和蹙迫性权重;关于输入任务和模子输出,judgemodel逐项给出分数,再通过平均、加权乞降或隐式团聚获取全体评价。
更蹙迫的是,论文对Rubrics与几个容易污染的看法进行了区分和筹划。LLM-as-a-Judge处理的是「谁来评」,Rubrics处理的是「按什么模范评」;rewardmodel经常径直输出一个标量分数,而Rubrics将评价模范显式列出;RLVR依赖自动可验证的谜底,而Rubrics更相宜那些需要多维度判断、难以整个验证的灵通式任务。
Rubrics如何构造?
Rubrics是否灵验,率先取决于它们自己是否弥散好。一个过于正常的模范,举例“回知道当有匡助”,很难提供沉着的考试和评测信号;一个过于细碎或类似的模范,又可能带来冗余评分和噪声。
综述将Rubrics构造步调区别为四类,呈现出节约单到复杂、从静态生成到动态演化的道路。
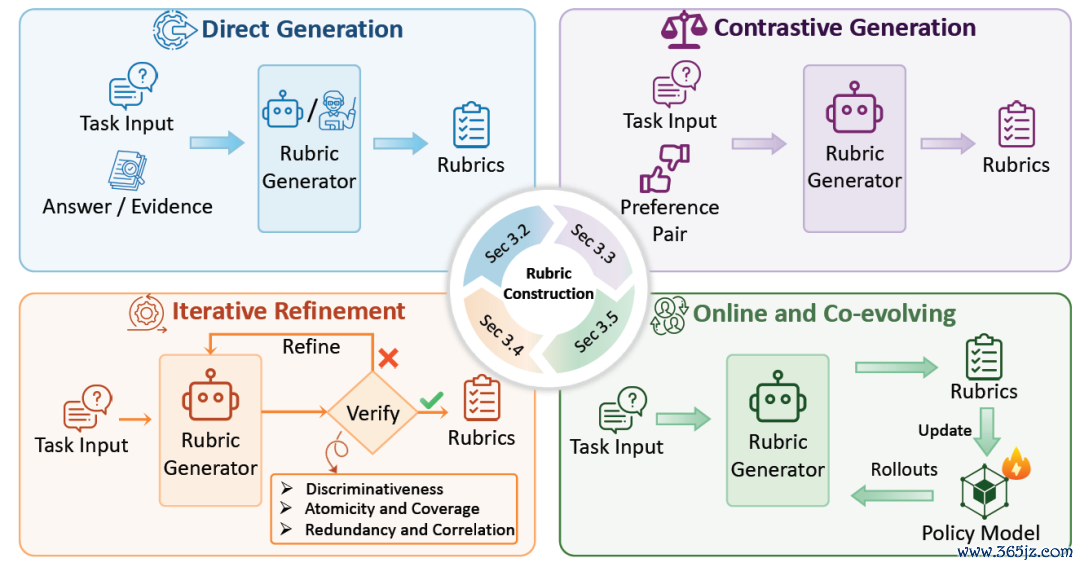
图2:四种不同的rubrics生成范式,包含径直生成、对比生成、迭代优化和在线演化。
第一类是径直生成。给定任务领导、候选谜底或参考据据,浩大的LLM不错一次性生成一组评价模范。
第二类是对比生成。比较只看一个谜底,对比生成会输入偏好对,举例一个高质料请问和一个低质料请问,让模子回来二者互异,从而索求更有判别力的模范。
第三类是迭代优化。筹划者运行不再把Rubrics构造当成一次生成任务,而是引入迭代地验证、领悟、过滤等历程。举例检测某个模范是否能沉着区分偏好对,递归拆分过粗的模范,最终获取更原子、更紧凑的rubricset。
幸运飞艇app2026世界杯中国官方下载第四类是在线与共同演化。关于强化学习和Agent任务来说,静态Rubrics可能很快逾期。因此,部单干作尝试让Rubrics跟着policyrollouts更新,将新出现的不实行径纳入评价模范,使Rubrics与模子考试过程共同演化。
Rubrics如何用于模子考试?
在模子考试中,Rubrics的中枢作用是把复杂质料要求转机为可优化的监督信号。比较一个全体偏好标签,Rubrics能告诉模子「那里作念得好、那里需要改」,因此尽头相宜灵通式任务和多步Agent任务。
用于policymodeltraining:让模子学会生成好谜底
模范的基于rubrics作念policyRL的方式是:给定输入和模子生成的请问,judgemodel按Rubrics逐项打分,再将分数团聚为一个奖励,用于PPO、GRPO等强化学习算法。这个过程不错作用在最终谜底上,也不错作用在完满轨迹上。关于器具调用Agent、深度筹划Agent或多模态推理模子,斗鱼体育app中国官网下载轨迹级Rubrics尤其蹙迫,因为许多不实并不会径直体当今最终谜底中。示例图如下:
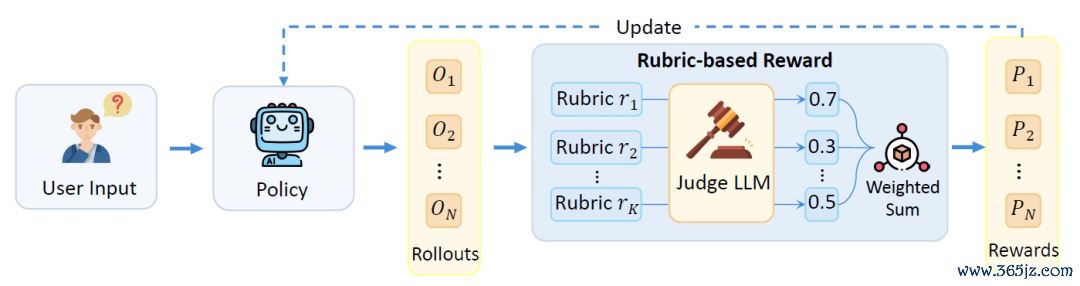
图3:四种不同的rubrics生成范式,包含径直生成、对比生成、迭代优化和在线演化。
不外,将多维Rubrics肤浅加权为一个标量奖励是比较粗粒度且不机动的,因为不同模范之间可能存在依赖、窒碍或硬阻抑关系。举例医疗问答中的安全性不应仅仅一个庸俗加分项,而可能是veto条款(一朝违抗则reward为0)。基于此,许多职责进一步提倡规划更先进更鲁棒的rubricreward:包括可学习的Rubric权重、引入veto或saturation机制、勾通环境响应、按难度进行curriculum考试,以及在RL算法里面勾通rubrics规划上风猜度。
还有一类职责将Rubrics从「过后打分器具」鼓励为「生成过程中的指挥」。模子不错先生成或读取Rubrics,再据此权术请问;也不错把未孤高的Rubric转机为响应,指挥下一轮改写。这意味着Rubrics不仅能告诉模子一个输出得几许分,还能匡助模子探索更高质料的输出空间。
用于rewardmodeltraining:让奖励模子更可讲解、更可靠
Rubrics也被越来越多地用于rewardmodeltraining。传统rewardmodel时时只输出一个标量分数,难以讲解为什么某个请问更好。引入Rubrics后,rewardmodel不错被考试为先依据模范进行分析,再给出偏好判断;也不错输出多个维度的分数,并通过显式团聚获取最终reward。根据综述的整理,Rubrics在rewardmodeltraining中主要施展三类作用。
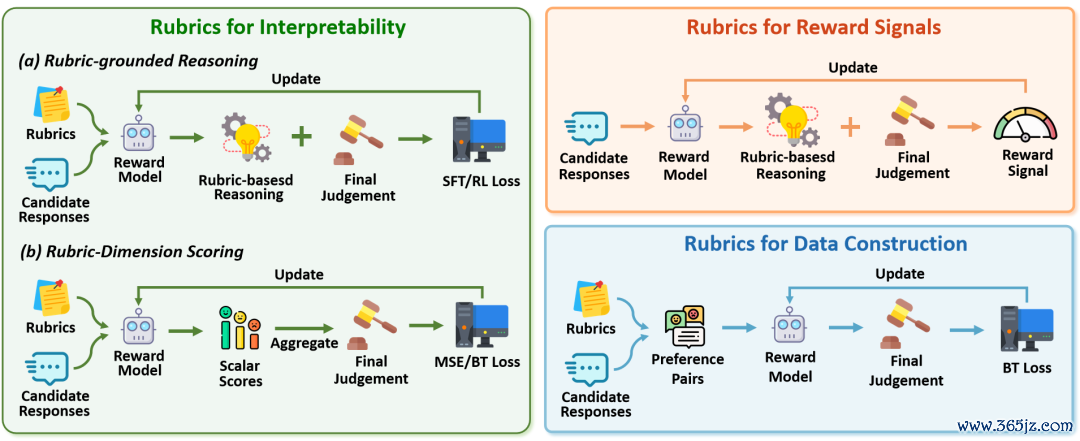
图4:rubrics在rewardmodel考试中的三类职责。
1.擢升奖励模子的可讲解性
传统rewardmodel经常径直输出一个标量分数,评价模范隐含在模子参数中,筹划者很难判断模子究竟依据什么作念出偏好判断。引入Rubrics后,奖励模子不错被考试为先围绕给定模范进行逐项分析,再输出最终偏好判断;也不错对不同rubric维度分别打分,再通过显式团聚获取最终reward。这么一来,奖励模子不再仅仅一个黑箱打分器,而是大约展示「为什么这个请问更好」「哪些维度影响了最终分数」。
2.提供更细粒度的rewardmodel考试信号
除了最终偏好是否正确以外,Rubrics还不错动作结构化参考单位,用来阻抑奖励模子的中间分析过程。举例,一些职责会将东说念主工标注或磨真金不怕火模子生成的根由拆解为rubric-level的参考信号,并在考试中荧惑rewardmodel的分析过程与这些模范保捏一致;也有步调要求模子先生成Rubrics,再进行分析和判断,并通过独特的proxymodel评估生成Rubrics的质料,从而把Rubrics自己也纳入优化主张。
3.用于构造更高质料的考试数据
传统偏好数据中时时包含长度、形状、口吻等浅层痕迹,rewardmodel可能学会这些名义特征,而不是学习真确决定请问质料的要素。Rubrics不错匡助识别影响请问质料的中枢维度,并据此构造更有针对性的考试样本,使奖励模子更温雅事实性、完满性、安全性、推理质料等本质模范,而不是依赖「请问更长」「形状更整皆」这种。
Rubrics如何用于评测?
除了考试,Rubrics另一个常见的用途是模子评测。关于灵通式任务,Rubrics特地于一份显式的评价模范:它界说了需要查抄的维度,如何给分等等。本文按照通用任务和范围特定的任务对已有的基于rubrics评估的benchmark进行了分类:
在通用任务中,Rubrics已被用于推理能力、深度筹划、灵通式生成、通用Agent能力和对皆评测。举例在数学推理任务中,评测不再只看最终谜底,还会查抄中间设施的正确性;深度筹划任务的评测会同期温雅信息覆盖、笔据复古等维度;Agent任务相关的评测则进一步温雅器具遴荐、参数调用、和多轮引申可靠性等方面。
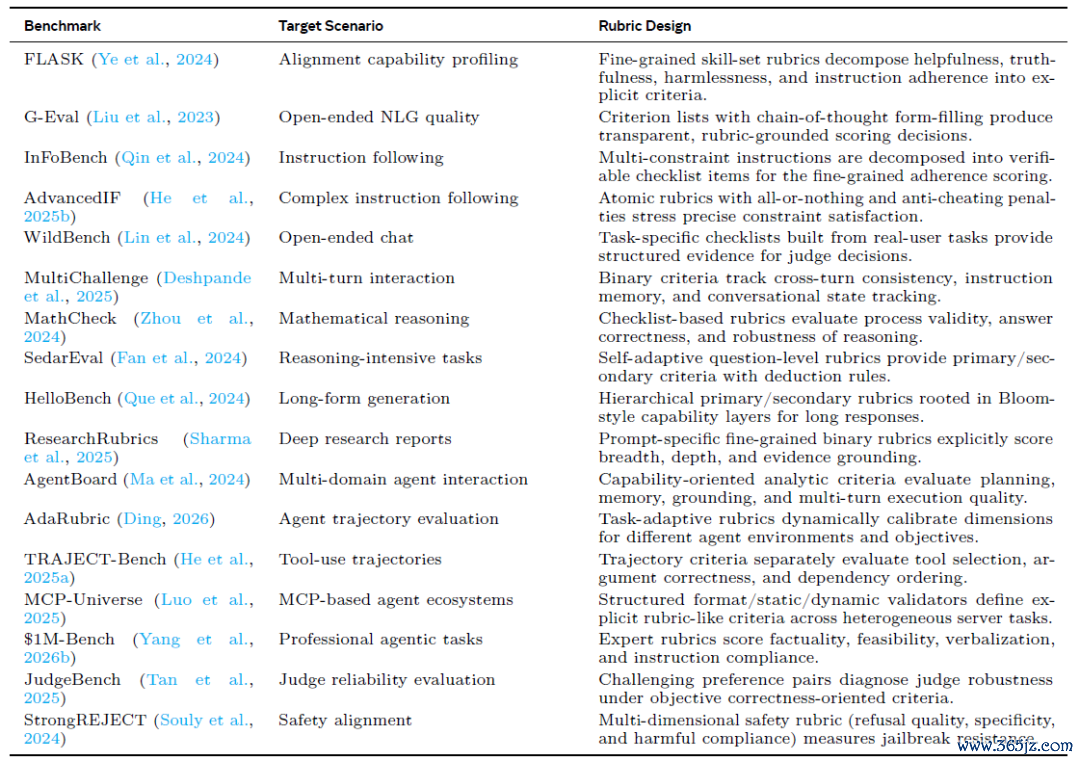
图5:rubrics在通用任务评估上的代表性职责。
在专科范围中,Rubrics的价值更彰着。举例,在医疗问答范围,东说念主们需要民众制定模范来查抄模子请问中的医学正确性、安全风险和交流质料等等;在法律和金融任务中,咱们需要评估事实适用、过程可审计、风险露馅和实务可操作性;在这部分,综述按照评估的对象(中间轨迹和最终谜底)和模范(事实性、安全性、专科抒发和本质可用性)对已有的职责进行了谨防的分类和筹划。
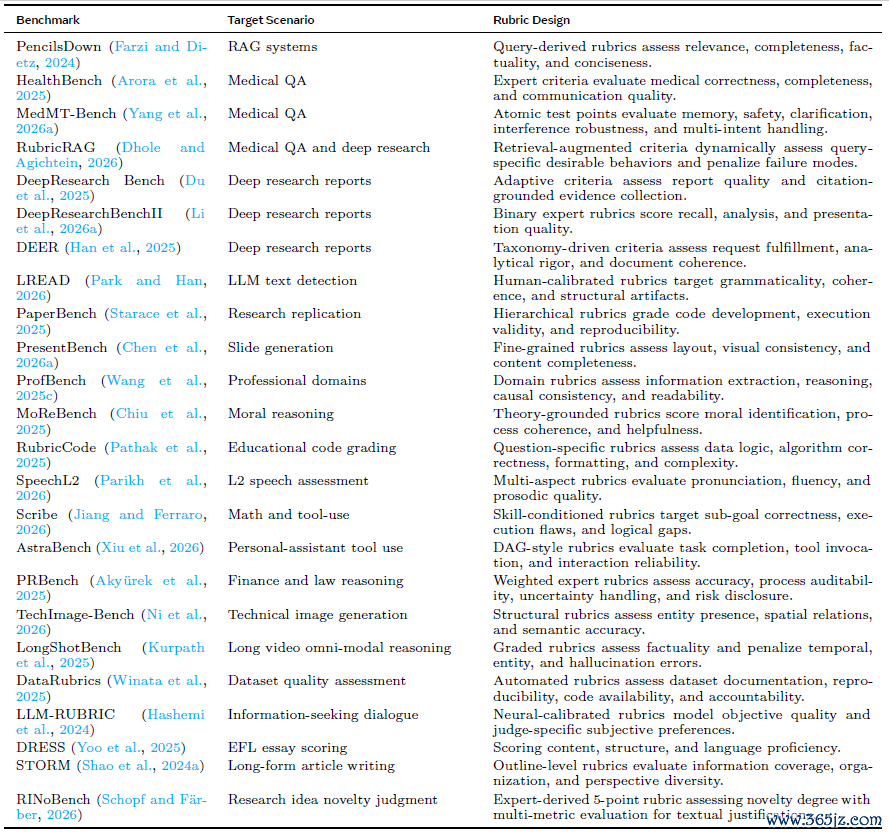
图6:rubrics在特定范围任务评估上的代表性职责。
灵通问题和挑战:Rubrics不是银弹
Rubrics的上风在于显式、结构化和可讲解,但这些特色也带来了新的问题。综述回来了多个值得温雅的灵通挑战。
率先是rewardhacking。模子在考试过程中可能学会hackrubrics的名义特征,而不是真确擢升任务质料。如何规划更端庄的Rubrics、并让规划Rubrics随考试过程的更新机制,是改日蹙迫标的。
其次是rubric-basedrewardmodel的泛化。许多Rubrics来自特定任务或范围,rewardmodel可能过拟合这些模范而丢失泛化性。改日需要筹划如何让奖励模子在新任务、新范围下仍然灵验地基于Rubrics进行reward算计,尤其是在医疗、法律、金融和科学推理等高门槛范围。
第三是评测偏差。Rubrics不错提高评测的可讲解性,但并弗成自动扬弃bias。Rubric的写法,judgemodel的中式等等都会对最终的评测产生bias。如何规划更鲁棒更沉着的Rubric-basedevaluation是一个需要处理的问题。
此外,个性化Rubrics和Rubric安全也正在成为新问题。个性化Rubrics不错更好地描写用户偏好,但也可能过度相投浅层偏好,以至与安全模范窒碍。与此同期,Rubrics自己也可能成为报复面:坏心或遮蔽的模范改写可能暗暗更动judge的偏好标的,并进一步影响考试数据和模子行径。
结语:把「规章」写明晰,才可能真确优化模子行径
这篇综述的中枢兴味,不仅仅成列了Rubrics相关职责,而是把一个正在快速扩展的筹划标的放进了和洽框架中:Rubrics是大模子考试与评测中的显式质料接口。它界说模范,组织响应,聚合东说念主类偏好、任务阻抑与模子优化。
跟着大模子持续走向灵通式、高风险和Agentic利用斗鱼体育app,系统需要的不仅仅更强的生成能力,还需要更明晰的质料界说。Rubrics的价值正在于此:它让「好谜底」不再仅仅一个迂缓直观,而成为一组不错筹划、查抄、修改和优化的明确模范。